




业界首个13B级别的MoE(混合专家)开源混合推理模型,以小参数实现大智慧。
6月27日,腾讯混元宣布开源首个混合推理MoE模型Hunyuan-A13B。这一模型总参数为80B,但激活参数仅为13B,以小参数实现了比肩同等架构领先开源模型的成绩,具有推理速度更快,性价比更高的优势。目前,该模型已经在Github和Huggingface等开源社区上线,同时模型API也在腾讯云官网正式上线,支持快速接入部署。
开源业界首个13B级别的MoE混合推理模型
据腾讯介绍,Hunyuan-A13B是腾讯内部应用和调用量最大的大语言模型之一,有超过400个业务用于精调或者直接调用,日均请求超1.3亿。同时,这也是业界首个13B级别的MoE开源混合推理模型,可以帮助开发者以用更低门槛的方式获得更好的模型能力。
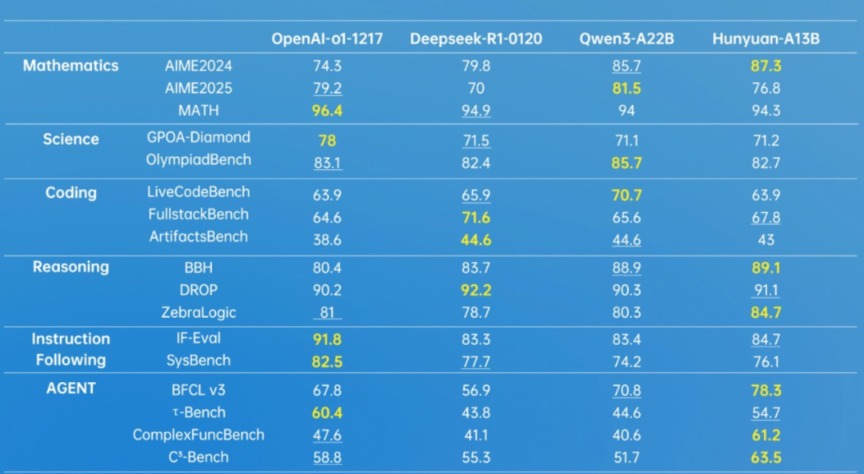
在多个业内权威数据测试集上,Hunyuan-A13B与OpenAI的o1-1217、DeepSeek的R1-0120、Qwen3-A22B等模型的对比中表现出了不相上下的成绩。
此外,今年2月,腾讯混元发布了新一代快思考模型TurboS,旨在将擅长快思考的TurboS与擅长慢思考的混元T1结合起来,弥补单一推理模型响应速度不及时的不足,让大模型更智能、更高效地解决问题。此次开源的Hunyuan-A13B可以根据需要选择快慢思考模式。腾讯混元表示,这种融合推理模式优化了计算资源分配,能够在效率和特定任务准确性之间取得平衡。
Hunyuan-A13B本次升级更新及对外开源,是腾讯继混元large后推出的又一重要开源模型,参数更小,但性能和效果实现了大幅的提升。腾讯混元表示,未来还计划推出将推出更多尺寸、更多特色的模型,适配企业与端侧不同需求,混元图像、视频、3D等多模态基础模型及配套插件模型也将持续开源。
持续加码AI,混元大模型研发体系全面重构
随着AI的竞争日渐激烈,腾讯在大模型领域的战略和部署正在持续进化。本次Hunyuan-A13B的更新升级与对外开源,是腾讯对其混元大模型研发体系进行全面重构之后的一大动作。
今年4月末,腾讯围绕算力、算法和数据三大核心板块,刷新团队部署,加码研发投入,新成立了大语言模型部和多模态模型部两个部门,分别负责探索大语言模型和多模态大模型的前沿技术,持续迭代基础模型,提升模型能力。
此外,腾讯还进一步加强了大模型数据能力和平台底座建设,数据平台部专注大模型数据全流程管理与建设,机器学习平台部则聚焦机器学习与大数据融合平台建设,为AI模型训练推理、大数据业务提供全面高效的PaaS平台底座,共同支撑腾讯混元大模型技术研发。
与此前的架构调整侧重于产品侧相比,本次调整主要针对技术侧,旨在增强腾讯混元大模型的研发实力。腾讯相关人士向记者表示,这意味着腾讯在快速调整组织架构以应对日新月异的大模型行业发展,这次调整有利于整合资源,优化研发流程,进一步提升腾讯在AI领域的长期技术作战能力。
腾讯发布的2024年年报显示,腾讯2024年研发投入达706.9亿元,资本开支连续四个季度实现同比三位数增长,年度资本开支更突破767亿元,同比增长221%,创历史新高。腾讯总裁刘炽平在财报电话会上表示,随着AI能力和价值的逐步显现,腾讯加大了AI投资,以满足内部业务需求、训练基础模型,并支持日益增长的推理需求。刘炽平同时透露,第四季度的资本支出增加非常显著,这是由于这一季度公司购买了更多GPU以满足推理需求,计划在2025年进一步增加资本支出。
 还未登录
还未登录









